Ранее я рассмотрел пример открытия файла CSV с яндекс-диска - Панда - открываем CSV c яндекс-диска
Подобным же способом его можно открыть и с Гугл-диска.
Путь к файлу у Гугл длиннее и выглядит подобным образом:
https://drive.google.com/file/d/xxxx123457yyyZZyZyZxxx_xYxYxxx_4x/view?usp=sharing
Нам потребуются те же самые импорты, но код будет несколько другим в части обработки адреса:
# задаем адрес нашего загруженного файла
addr = 'https://drive.google.com/file/d/xxxx123457yyyZZyZyZxxx_xYxYxxx_4x/view?usp=sharing'
# формируем путь для загрузки
path = 'https://drive.google.com/uc?export=download&id='+addr.split('/')[-2]
# в path теперь будет что-то типа такого
# https://drive.google.com/uc?export=download&
# id=xxxx123457yyyZZyZyZxxx_xYxYxxx_4x
Далее действуем как в случае яндекс-диска:
download_response = requests.get(path)
csv_raw = StringIO( download_response.content.decode('cp866'))
df = pd.read_csv(csv_raw, sep=';')
В результате данные загружены.
29 June 2020
28 June 2020
Задача двух осей и четырех графиков - игра с matplotlib
В посте выше Задача двух осей и четырех графиков - введение мы посмотрели как сделать модельные данные.
Давайте теперь поиграем с библиотекой при рисовании.
Пусть нам надо сделать два графика, по два набора данных.
Однако такой простой код тут нам не поможет:
# рисуем x,y реальные и модельные, причем для модельный точками зеленого цвета
# 'go' - первая буква от green, вторая - кружочки
plt.plot( x,y , x,yr ,'go')
# рисуем x,y2 реальные и модельные, причем для модельный точками синего цвета
plt.plot( x,y2 , x,yr2 ,'bo')
Как можно видеть - задача не достигнута и все нарисовалось на одном графике.

Поэтому в данном случае имеет смысл разбить холст на области.
В терминологии matplotlib то, что я называю холст - это figure - объект-контейнер самого высокого уровня. Соответственно область - это axes, которая создается вызовом subplot или subplots.
Проще в использовании subplot, которые принимает на вход три цифры через запятую или одну трехзначную цифру и позволяет создать область.
Вот новый код:
# создаем первую область:
# первая 2 - количество областей по вертикали (rows)
# вторая 1 - количество областей по горизонтали (cols)
# третья 1 - индекс - первая область
plt.subplot(211)
plt.plot( x,y , x,yr ,'go')
# создаем вторую область с индексом 2 соответственно
plt.subplot(212)
plt.plot( x,y2 , x,yr2 ,'bo')
Теперь мы получили уже то, что надо

Второй способ - использовать вызов subplots, который вернет figure и
массив axes:
# создаем области - две по вертикиали в одну колонку
# и запоминаем ссылку на холст(фигуру) и области(оси)
fig, ax = plt.subplots(2,1)
# рисуем первый график в первой области
ax[0].plot( x,y , x,yr ,'go')
# рисуем второй график во второй области
ax[1].plot( x,y2 , x,yr2 ,'bo')
Этот код нарисует в точности такой же рисунок как и выше.
Давайте теперь поиграем с библиотекой при рисовании.
Пусть нам надо сделать два графика, по два набора данных.
Однако такой простой код тут нам не поможет:
# рисуем x,y реальные и модельные, причем для модельный точками зеленого цвета
# 'go' - первая буква от green, вторая - кружочки
plt.plot( x,y , x,yr ,'go')
# рисуем x,y2 реальные и модельные, причем для модельный точками синего цвета
plt.plot( x,y2 , x,yr2 ,'bo')
Как можно видеть - задача не достигнута и все нарисовалось на одном графике.

Поэтому в данном случае имеет смысл разбить холст на области.
В терминологии matplotlib то, что я называю холст - это figure - объект-контейнер самого высокого уровня. Соответственно область - это axes, которая создается вызовом subplot или subplots.
Проще в использовании subplot, которые принимает на вход три цифры через запятую или одну трехзначную цифру и позволяет создать область.
Вот новый код:
# создаем первую область:
# первая 2 - количество областей по вертикали (rows)
# вторая 1 - количество областей по горизонтали (cols)
# третья 1 - индекс - первая область
plt.subplot(211)
plt.plot( x,y , x,yr ,'go')
# создаем вторую область с индексом 2 соответственно
plt.subplot(212)
plt.plot( x,y2 , x,yr2 ,'bo')
Теперь мы получили уже то, что надо

Второй способ - использовать вызов subplots, который вернет figure и
массив axes:
# создаем области - две по вертикиали в одну колонку
# и запоминаем ссылку на холст(фигуру) и области(оси)
fig, ax = plt.subplots(2,1)
# рисуем первый график в первой области
ax[0].plot( x,y , x,yr ,'go')
# рисуем второй график во второй области
ax[1].plot( x,y2 , x,yr2 ,'bo')
Этот код нарисует в точности такой же рисунок как и выше.
26 June 2020
Задача двух осей и четырех графиков - введение

Этого, пожалуй, вполне хватит, если речь идет только о моделировании и вот почему:
на графиках, хоть и разный масштаб, но интересна динамика, поэтому даже учитывая малую амплитуду для данных Infected и Death мы тут видим качественное изменение, что вполне достаточно для анализа.
Теперь представим себе другой случай - мы не просто моделируем, но и смотрим соответствие модели экспериментальным данным.
Тогда:
- количество графиков удваивается - надо показывать как модельные так и реальные данные
- масштаб играет роль - насколько модель будет отражать реальные данные для того же графика Death при мелком размере графика будет непонятно.
Для симуляции модельных данных я буду брать модель синуса и косинуса, а для симуляции реальных данных - просто добавлю туда случайные величины.
По факту для работы нам достаточно импортировать только NumPy:
import numpy as np
Данные будут храниться в глобальных переменных. Пусть амплитуды будут различаться.
Пусть ось x будет одинаковая.
Возьмем для примера два набора - y и y2, реальные данные будут тогда yr и yr2 соответственно:
x, y, y2, yr, yr2 = [], [], [], [], []
Теперь сначала вычислим данные для модельных наборов:
# параметры тригонометрический функций
f = 0.5; phase = 2
# 10 значений по оси х
x = np.linspace(0, 10, 10)
# y будет синусом
y = np.sin(f * x + phase)
# y2 будет косинусом с пятикратно более высокой амплитудой
y2 = 5*np.cos(f * x + phase)
Далее смоделируем реальные данные. Вычислять их будем по модельным, используя векторные возможности NumPy:
yr = y + np.random.random() * y
yr2 = y2 + np.random.random() * y2
Т.е. в каждой точке данные получаются умножением случайного числа в диапазоне (0,1) на модельные данные.
Если хочется решить задачу при минимальном кодировании, то логично сделать два графика - для y и для y2:

Если хочется уплотнить информацию - удобнее эти два графика сделать на одном, но с двумя осями.

Второй способ - более тяжелый с точки зрения кодирования, но более компактный: скажем в случае SEIRD модели надо четыре величины и их можно упаковать в два графика.
В дальнейшем мы эти варианты последовательно рассмотрим.
24 June 2020
Панда - открываем CSV c яндекс-диска
Одна из задач, которая возникла у меня - перенос с одного компа с Windows и Excel данные на виртуалку с Убунтой. Чтобы не заморачиваться с копированием файлов можно выложить CSV, полученный из Excel на яндекс-диск и открыть его в Юпитере Пандой.
Ссылка для доступа будет иметь вид примерной такой :
https://yadi.sk/d/xxYYYzzzKKKzY
Для начала экспортируем то, что надо
import pandas as pd
import requests
from io import StringIO
from urllib.parse import urlencode
Далее заводим строчки:
# адрес на api яндекса
base_url = 'https://cloud-api.yandex.net/v1/disk/public/resources/download?'
# Наша ссылка
public_key = 'https://yadi.sk/d/xxYYYzzzKKKzY'
Далее загружаем файл:
# Получаем загрузочную ссылку
final_url = base_url + urlencode(dict(public_key=public_key))
response = requests.get(final_url)
download_url = response.json()['href']
# Загружаем файл и сохраняем его
download_response = requests.get(download_url)
Формально можно записать файл, а потом подать его панде:
with open('temp.csv', 'wb') as f:
f.write(download_response.content)
df = pd.read_csv('temp.csv')
Однако в данном случае Панда вылетит с ошибкой.
Причина тут вот какая: если вы сохраняете файл в CSV формате в Excel то используете MS-DOS CSV и у вас разделитель полей - точка с запятой, а не запятая, как в обычном CSV. Файл, с разделениям точкой с запятой, "умная" Панда читать отказывается.
Поэтому надо ей подсказать разделитель. Вот так:
df = pd.read_csv('temp.csv', sep=';')
Но и это не все - русские символы кодируются в кодировке cp866.
Поэтому если нужно перенести корректно русские данные, надо перекодировать символы в другую кодировку.

Собирая это все вместе и обходясь без промежуточного файла ( он желателен при отладке ), получаем:
# Перекодируем из cp866
csv_raw = StringIO( download_response.content.decode('cp866'))
# Читаем пандой прямо из буфера, подставляя нужный разделитель
df = pd.read_csv(csv_raw, sep=';')
Вот получившиеся данные:

Ответ был подсмотрен тут : как скачивать файлы с яндекс диска
Ссылка для доступа будет иметь вид примерной такой :
https://yadi.sk/d/xxYYYzzzKKKzY
Для начала экспортируем то, что надо
import pandas as pd
import requests
from io import StringIO
from urllib.parse import urlencode
Далее заводим строчки:
# адрес на api яндекса
base_url = 'https://cloud-api.yandex.net/v1/disk/public/resources/download?'
# Наша ссылка
public_key = 'https://yadi.sk/d/xxYYYzzzKKKzY'
Далее загружаем файл:
# Получаем загрузочную ссылку
final_url = base_url + urlencode(dict(public_key=public_key))
response = requests.get(final_url)
download_url = response.json()['href']
# Загружаем файл и сохраняем его
download_response = requests.get(download_url)
Формально можно записать файл, а потом подать его панде:
with open('temp.csv', 'wb') as f:
f.write(download_response.content)
df = pd.read_csv('temp.csv')
Однако в данном случае Панда вылетит с ошибкой.
Причина тут вот какая: если вы сохраняете файл в CSV формате в Excel то используете MS-DOS CSV и у вас разделитель полей - точка с запятой, а не запятая, как в обычном CSV. Файл, с разделениям точкой с запятой, "умная" Панда читать отказывается.
Поэтому надо ей подсказать разделитель. Вот так:
df = pd.read_csv('temp.csv', sep=';')
Но и это не все - русские символы кодируются в кодировке cp866.
Поэтому если нужно перенести корректно русские данные, надо перекодировать символы в другую кодировку.

Собирая это все вместе и обходясь без промежуточного файла ( он желателен при отладке ), получаем:
# Перекодируем из cp866
csv_raw = StringIO( download_response.content.decode('cp866'))
# Читаем пандой прямо из буфера, подставляя нужный разделитель
df = pd.read_csv(csv_raw, sep=';')
Вот получившиеся данные:

Ответ был подсмотрен тут : как скачивать файлы с яндекс диска
20 June 2020
Plotly - задача о двух графиках в Юпитере
В прощлый раз сделать интерактивными два графика, которые рисует matplotlib,как я показал - вовсе не тривиальна - они начинают плодиться.
Посмотрим как это же самое решается посредством библиотеки plotly.
Для начала импортируем нужные библиотеки:
import numpy as np
import ipywidgets as widgets
from IPython.display import clear_output
import plotly.graph_objects as go
from plotly.subplots import make_subplots
Функция вычисления у нас такая же:
x, y, y2 = [], [], []
def calc(f, phase):
global x,y,y2
x = np.linspace(0, 10, 100)
y = np.sin(f * x + phase)
y2 = np.cos(f * x + phase)
А вот графики в plotly создаются по-другому:
# создаем виджет для холста с двумы строками в одну колонку
fv = go.FigureWidget(make_subplots(rows=2, cols=1))
# создаем первый график - для y - он в первой строке
fv.add_trace(
go.Scatter(x=x, y=y, name="yaxis data"),row=1,col=1
)
# создаем второй график - для y2 - он во второй строке
fv.add_trace(
go.Scatter(x=x, y=y2, name="yaxis2 data"),row=2,col=1
)
# Устанавливаем название графика - Double Y Axis Example
fv.update_layout( title_text="Double Y Axis Example" )
# Делаем подпись оси x
# если не запомнить это в безликую переменную "_"
# то после выполнения этой команды
# сразу покажутся два пустых графика
_ =fv.update_xaxes(title_text="xaxis title")
Функция рисования теперь тоже отличается - нам нужно просто присвоить
данные графикам:
def plot_f(f, phase):
global x,y,y2, fv
calc(f, phase)
fv.data[0].x = x
fv.data[0].y = y
fv.data[1].x = x
fv.data[1].y = y2
В данном случае индекс идет по порядку добавления - мы добавили первым
первый график и он идет с индексом 0, а второй - с индексом 1.
Создание виджетов и обработчик кнопки не отличаются от таких же как в примере с matplotlib
И после их выполнения - т.е. выполнения последней строчки создания VBox мы увидим то, что нам нужно:

после того, как движками мы изменим значения и нажмем кнопку, график обновится:
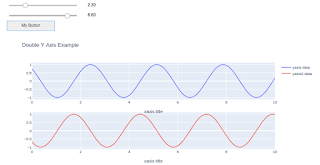
При каждом новом нажатии кнопки график будет обновляться, но не рисоваться дополнительно.
Посмотрим как это же самое решается посредством библиотеки plotly.
Для начала импортируем нужные библиотеки:
import numpy as np
import ipywidgets as widgets
from IPython.display import clear_output
import plotly.graph_objects as go
from plotly.subplots import make_subplots
Функция вычисления у нас такая же:
x, y, y2 = [], [], []
def calc(f, phase):
global x,y,y2
x = np.linspace(0, 10, 100)
y = np.sin(f * x + phase)
y2 = np.cos(f * x + phase)
А вот графики в plotly создаются по-другому:
# создаем виджет для холста с двумы строками в одну колонку
fv = go.FigureWidget(make_subplots(rows=2, cols=1))
# создаем первый график - для y - он в первой строке
fv.add_trace(
go.Scatter(x=x, y=y, name="yaxis data"),row=1,col=1
)
# создаем второй график - для y2 - он во второй строке
fv.add_trace(
go.Scatter(x=x, y=y2, name="yaxis2 data"),row=2,col=1
)
# Устанавливаем название графика - Double Y Axis Example
fv.update_layout( title_text="Double Y Axis Example" )
# Делаем подпись оси x
# если не запомнить это в безликую переменную "_"
# то после выполнения этой команды
# сразу покажутся два пустых графика
_ =fv.update_xaxes(title_text="xaxis title")
Функция рисования теперь тоже отличается - нам нужно просто присвоить
данные графикам:
def plot_f(f, phase):
global x,y,y2, fv
calc(f, phase)
fv.data[0].x = x
fv.data[0].y = y
fv.data[1].x = x
fv.data[1].y = y2
В данном случае индекс идет по порядку добавления - мы добавили первым
первый график и он идет с индексом 0, а второй - с индексом 1.
Создание виджетов и обработчик кнопки не отличаются от таких же как в примере с matplotlib
И после их выполнения - т.е. выполнения последней строчки создания VBox мы увидим то, что нам нужно:

после того, как движками мы изменим значения и нажмем кнопку, график обновится:

При каждом новом нажатии кнопки график будет обновляться, но не рисоваться дополнительно.
15 June 2020
Plotly установка и полезные ссылки
Формально, для установки plotly надо выполнить
pip install cufflinks plotly
cufflinks - это для работы с plotly в pandas.
Однако для Юпитера мне пришлось еще добавочно ставить через анаконду
conda install -c plotly plotly-orca
Одна из первых русскоязычных ссылок, которая составляет неплохой обзор
по plotly это Забудьте о matplotlib: визуализация данных в Python вместе с plotly
Сам же код лучше смотреть непосредственно на англоязычной странице, откуда сделан перевод Plotly Whirlwind Introduction - Jupiter Notebook
Для использования примеров с этой страице желательно локально скачать данные вот отсюда: Data for Plotly Whirlwind Introduction
Оттуда нужет вот этот файл - medium_data_2019_01_06 ( достаточно большой )
Для того, чтобы его можно было отркрыть надо ставить поддежку parquet такой командой
pip install pyarrow fastparquet
Сам parquet - сжатый колонно-ориентированный формат от Апача
parquet format
Также после за справкой лучше идти на сам сайт plotly
Plotly Creating and Updating Figures in Python
pip install cufflinks plotly
cufflinks - это для работы с plotly в pandas.
Однако для Юпитера мне пришлось еще добавочно ставить через анаконду
conda install -c plotly plotly-orca
Одна из первых русскоязычных ссылок, которая составляет неплохой обзор
по plotly это Забудьте о matplotlib: визуализация данных в Python вместе с plotly
Сам же код лучше смотреть непосредственно на англоязычной странице, откуда сделан перевод Plotly Whirlwind Introduction - Jupiter Notebook
Для использования примеров с этой страице желательно локально скачать данные вот отсюда: Data for Plotly Whirlwind Introduction
Оттуда нужет вот этот файл - medium_data_2019_01_06 ( достаточно большой )
Для того, чтобы его можно было отркрыть надо ставить поддежку parquet такой командой
pip install pyarrow fastparquet
Сам parquet - сжатый колонно-ориентированный формат от Апача
parquet format
Также после за справкой лучше идти на сам сайт plotly
Plotly Creating and Updating Figures in Python
14 June 2020
Юпитер и интерактивность - темная строна
Давайте теперь попробуем вывести уже два графика. Для того, чтобы разместить их на одном полотне, используется функция sublots, которая выделает под это области для каждого графика. Вычисления мы тоже немного усложним - добавим данные для второго графика в y2
# глобальные x, y и y2
x, y, y2 = [], [], []
# вычисляем их в отдельной функции с двумя параметрами
def calc(f, phase):
global x,y,y2
x = np.linspace(0, 10, 100)
y = np.sin(f * x + phase)
y2 = np.cos(f * x + phase)
Также усложнится функция рисования
# функция рисивания с двумя параметрами
# перед рисованием она вызывает функцию calc для обновления данных
def plot_f(f, phase):
global x,y,y2
calc(f, phase)
# само рисование
# создаем две области рисования по вертикали в одной колонке
# сами области будут доступны из списка ax
# делаем высоту ( 4 ) поменьше
fig, ax = plt.subplots(2,1,figsize=(16,4), dpi= 80)
# добавляем к первой области сетку
ax[0].grid(True,c='black')
# рисуем первую область
ax[0].plot(x,y, color='tab:red', marker='D')
# добавляем ко второй области сетку
ax[1].grid(True,c='black')
# рисуем первую область
ax[1].plot(x,y2, color='tab:blue', marker='D')
Обработчик кнопки остается тем же самым - мы поменяли функцию рисования.
И вот тут начинаются чудеса.
При первом вызове мы видим два нужных графика, но как уже
видно на снимке - график появился непосредственно за виджетам, а не
в outt

И вот уже второй вызов просто дает нам еще одну пару графиков там же

Все... приехали... - интерактивность совершенно разрушилась.
Для примеров я просмотрел и вот этут статью
Ipywidgets with matplotlib
Однако тот подход тоже не помогает.
В самом деле - давайте попробуем создать графики в глобальном пространстве, а потом использовать замену данных в функции рисования
Поэтому сначала создадим outt
outt = widgets.Output()
А потом нарисуем в глобальном пространстве с его указанием
with outt:
fig, ax = plt.subplots(2,1,figsize=(16,4), dpi= 80)
ax[0].grid(True,c='black')
ln, = ax[0].plot(x,y, color='tab:red', marker='D')
ax[1].grid(True,c='black')
ln2, = ax[1].plot(x,y2, color='tab:blue', marker='D')
Так вот, графики уже нарисуются после этого вызова, разумеется пустые - мы же ни разу функцию вычисления не дергали и списки - пустые

Теперь поменяем функцию рисования - пусть она будет ставить данные на существующие графики, для начала на один
def plot_f(f, phase):
global x,y,y2, ax, ln, fig
calc(f, phase)
ln.set_xdata(x)
ln.set_ydata(y)
plt.show()
Меняем значения и нажимаем кнопку - и ... ничего не происходит. Новых графиков не пояляется, а на старом ничего не изменилось. При этом данные присутствуют - достаточно набрать в отдельной ячейке y и убедиться в этом.
Даже пример с той ссылки работает некорректно

Как можно видеть - график появился не после output, а сразу за выполеным кодом.
Если же попробовать выполнить магическую команду %matplotlib widget, упомянутую в статье, то она свалится с ошибкой

Суть которой в конце такая: ModuleNotFoundError: No module named 'ipympl'
В статье указан такой список:
Python 3.8.1
matplotlib 3.1.3
NumPy 1.18.1
ipywidgets 7.5.1
ipympl 0.4.1
Запустим conda list прямо в Юпитере и смотрим что у меня:
python 3.7.6 h0371630_2
matplotlib 3.1.3 py37_0
numpy 1.18.1 py37h4f9e942_0
ipywidgets 7.5.1 py_0
...И нет ipympl
В общем, ipympl сразу в дистрибутиве не идет и надо его ставить отдельно.
Но к тому времени, как я убил много попыток на то, чтобы заставить это
работать, я пришел к другому решению - поставил plotly
# глобальные x, y и y2
x, y, y2 = [], [], []
# вычисляем их в отдельной функции с двумя параметрами
def calc(f, phase):
global x,y,y2
x = np.linspace(0, 10, 100)
y = np.sin(f * x + phase)
y2 = np.cos(f * x + phase)
Также усложнится функция рисования
# функция рисивания с двумя параметрами
# перед рисованием она вызывает функцию calc для обновления данных
def plot_f(f, phase):
global x,y,y2
calc(f, phase)
# само рисование
# создаем две области рисования по вертикали в одной колонке
# сами области будут доступны из списка ax
# делаем высоту ( 4 ) поменьше
fig, ax = plt.subplots(2,1,figsize=(16,4), dpi= 80)
# добавляем к первой области сетку
ax[0].grid(True,c='black')
# рисуем первую область
ax[0].plot(x,y, color='tab:red', marker='D')
# добавляем ко второй области сетку
ax[1].grid(True,c='black')
# рисуем первую область
ax[1].plot(x,y2, color='tab:blue', marker='D')
Обработчик кнопки остается тем же самым - мы поменяли функцию рисования.
И вот тут начинаются чудеса.
При первом вызове мы видим два нужных графика, но как уже
видно на снимке - график появился непосредственно за виджетам, а не
в outt

И вот уже второй вызов просто дает нам еще одну пару графиков там же

Все... приехали... - интерактивность совершенно разрушилась.
Для примеров я просмотрел и вот этут статью
Ipywidgets with matplotlib
Однако тот подход тоже не помогает.
В самом деле - давайте попробуем создать графики в глобальном пространстве, а потом использовать замену данных в функции рисования
Поэтому сначала создадим outt
outt = widgets.Output()
А потом нарисуем в глобальном пространстве с его указанием
with outt:
fig, ax = plt.subplots(2,1,figsize=(16,4), dpi= 80)
ax[0].grid(True,c='black')
ln, = ax[0].plot(x,y, color='tab:red', marker='D')
ax[1].grid(True,c='black')
ln2, = ax[1].plot(x,y2, color='tab:blue', marker='D')
Так вот, графики уже нарисуются после этого вызова, разумеется пустые - мы же ни разу функцию вычисления не дергали и списки - пустые

Теперь поменяем функцию рисования - пусть она будет ставить данные на существующие графики, для начала на один
def plot_f(f, phase):
global x,y,y2, ax, ln, fig
calc(f, phase)
ln.set_xdata(x)
ln.set_ydata(y)
plt.show()
Меняем значения и нажимаем кнопку - и ... ничего не происходит. Новых графиков не пояляется, а на старом ничего не изменилось. При этом данные присутствуют - достаточно набрать в отдельной ячейке y и убедиться в этом.
Даже пример с той ссылки работает некорректно

Как можно видеть - график появился не после output, а сразу за выполеным кодом.
Если же попробовать выполнить магическую команду %matplotlib widget, упомянутую в статье, то она свалится с ошибкой

Суть которой в конце такая: ModuleNotFoundError: No module named 'ipympl'
В статье указан такой список:
Python 3.8.1
matplotlib 3.1.3
NumPy 1.18.1
ipywidgets 7.5.1
ipympl 0.4.1
Запустим conda list прямо в Юпитере и смотрим что у меня:
python 3.7.6 h0371630_2
matplotlib 3.1.3 py37_0
numpy 1.18.1 py37h4f9e942_0
ipywidgets 7.5.1 py_0
...И нет ipympl
В общем, ipympl сразу в дистрибутиве не идет и надо его ставить отдельно.
Но к тому времени, как я убил много попыток на то, чтобы заставить это
работать, я пришел к другому решению - поставил plotly
Юпитер и интерактивность - кнопка с графиком
Рассмотрим теперь возможность строить графики и для этого добавим вычисление данных.
Я сознательно сделаю сами данные как глобальные и добавлю функцию для их вычисления
# глобальные x и y
x, y = [], []
# вычисляем их в отдельной функции с двумя параметрами
def calc(f, phase):
global x,y
x = np.linspace(0, 10, 100)
y = np.sin(f * x + phase)
Для рисования создадим отдельную функцию, которая будет использовать глобальные данные
# функция рисования с двумя параметрами
# перед рисованием она вызывает функцию calc для обновления данных
def plot_f(f, phase):
global x,y
calc(f, phase)
# само рисование
plt.plot(x, y, 'r')
plt.show()
Сообразно нам надо поменять и обработчик нажатия кнопки
outt = widgets.Output()
def on_butt_clicked(b):
with outt:
clear_output()
global sF,sPhase
print ('Clicked')
print(sF.value, sPhase.value)
# вызываем рисование
plot_f(sF.value, sPhase.value)
button.on_click(on_butt_clicked)
widgets.VBox([sF, sPhase, button ])
Запускаем пример и делаем вывод outt - все работает как надо и в outt как раз наш график, которые перерисовывается при нажатии кнопки.

Обычно, описывая интерактивность Юпитера, блоггеры далее подобных примеров не идут, и, как можно видеть, все работает.
Однако если мы хотим рисовать что-то посложнее, то все становится не так просто, но об этом отдельно.
Я сознательно сделаю сами данные как глобальные и добавлю функцию для их вычисления
# глобальные x и y
x, y = [], []
# вычисляем их в отдельной функции с двумя параметрами
def calc(f, phase):
global x,y
x = np.linspace(0, 10, 100)
y = np.sin(f * x + phase)
Для рисования создадим отдельную функцию, которая будет использовать глобальные данные
# функция рисования с двумя параметрами
# перед рисованием она вызывает функцию calc для обновления данных
def plot_f(f, phase):
global x,y
calc(f, phase)
# само рисование
plt.plot(x, y, 'r')
plt.show()
Сообразно нам надо поменять и обработчик нажатия кнопки
outt = widgets.Output()
def on_butt_clicked(b):
with outt:
clear_output()
global sF,sPhase
print ('Clicked')
print(sF.value, sPhase.value)
# вызываем рисование
plot_f(sF.value, sPhase.value)
button.on_click(on_butt_clicked)
widgets.VBox([sF, sPhase, button ])
Запускаем пример и делаем вывод outt - все работает как надо и в outt как раз наш график, которые перерисовывается при нажатии кнопки.

Обычно, описывая интерактивность Юпитера, блоггеры далее подобных примеров не идут, и, как можно видеть, все работает.
Однако если мы хотим рисовать что-то посложнее, то все становится не так просто, но об этом отдельно.
13 June 2020
Юпитер и интерактивность - кнопки
Одна из прелестей Юпитера - возможность интерактивности.
Например можно использовать @interact и перерисовывать графики.
Хороший пример можно посмотреть тут Интерактивность в Jupyter Notebook
Однако если использовать перерисовку непостредственно по слайдеру, то это более тормознуто - график моргает при перемещении движка. Причем он может делать это с запаздыванием. Поэтому я стал смотреть возможности использования кнопок.
В самом деле - мне удобнее подвигать движки и потом, нажав кнопку, получить результат. Пример кнопок есть тут How to create buttons in Jupyter
Получилось это у меня не стразу - то при нажатии ничего не рисовалось, то наоборот рисовалось одно за другим - т.е. новый график просто добавлялся, что было неудобно.
Поэтому пришлось сделать пример и разобраться как оно работает
Для начала экспортируем то, что потребуется
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import interact
import ipywidgets as widgets
from IPython.display import clear_output
Далее создаем два слайдера и кнопку
button = widgets.Button(description='My Button')
sF = widgets.FloatSlider(
value=1,
min=0,
max=10.0,
step=0.1,)
sPhase = widgets.FloatSlider(
value=1,
min=0,
max=10.0,
step=0.1,)
Далее мне хотелось это вертикально разместить одно за другим - через VBox.
Однако, если результат записать в переменную вот так:
box = widgets.VBox([sF, sPhase, button ])
То ничего мы не увидим пока явно не выведем эту переменную например так

Но можно сделать проще - не записывать это в переменную, вот так:
widgets.VBox([sF, sPhase, button ])
Тогда это сразу отобразится.
Теперь настало время добавить функцию-обработчик, чтобы получить значения и напечатать их. Для доступа к значению у слайдера используется свойство value, причем поскольку создали мы его выше, то сначала внутри функции надо их объявить как глобальные, чтобы иметь доступ именно к созданным ранее

После запуска данной строки создается и два слайдера и кнопка и при нажатии кнопки печатается Clicked плюс значения слайдеров.
Все работает, но есть один ньюанс - при каждом нажатии печатаеся новая строка. Ровно тоже самое будет с графиками - они начнут плодиться, что неудобно.
Для очистки надо воспользоваться объектом widgets.Output() и обрамить функцию для его использования, используя конструкцию with

При запуске этого кода мы получим элемены управления но ... ничего происходить не будет.
Т.е. при нажатии кнопки мы вообще ничего не увидим. Поэтому строкой ниже можно просто вывести созданный Output() - вот там все и будет отображаться

Теперь все заработало как надо - строка обновляется и не рисуется еще одна.
Ровно то же можно использовать для графиков.
На понимание этого у меня ушло пару недель "шаманства" - понял я это не сразу.
Например можно использовать @interact и перерисовывать графики.
Хороший пример можно посмотреть тут Интерактивность в Jupyter Notebook
Однако если использовать перерисовку непостредственно по слайдеру, то это более тормознуто - график моргает при перемещении движка. Причем он может делать это с запаздыванием. Поэтому я стал смотреть возможности использования кнопок.
В самом деле - мне удобнее подвигать движки и потом, нажав кнопку, получить результат. Пример кнопок есть тут How to create buttons in Jupyter
Получилось это у меня не стразу - то при нажатии ничего не рисовалось, то наоборот рисовалось одно за другим - т.е. новый график просто добавлялся, что было неудобно.
Поэтому пришлось сделать пример и разобраться как оно работает
Для начала экспортируем то, что потребуется
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import interact
import ipywidgets as widgets
from IPython.display import clear_output
Далее создаем два слайдера и кнопку
button = widgets.Button(description='My Button')
sF = widgets.FloatSlider(
value=1,
min=0,
max=10.0,
step=0.1,)
sPhase = widgets.FloatSlider(
value=1,
min=0,
max=10.0,
step=0.1,)
Далее мне хотелось это вертикально разместить одно за другим - через VBox.
Однако, если результат записать в переменную вот так:
box = widgets.VBox([sF, sPhase, button ])
То ничего мы не увидим пока явно не выведем эту переменную например так

Но можно сделать проще - не записывать это в переменную, вот так:
widgets.VBox([sF, sPhase, button ])
Тогда это сразу отобразится.
Теперь настало время добавить функцию-обработчик, чтобы получить значения и напечатать их. Для доступа к значению у слайдера используется свойство value, причем поскольку создали мы его выше, то сначала внутри функции надо их объявить как глобальные, чтобы иметь доступ именно к созданным ранее

После запуска данной строки создается и два слайдера и кнопка и при нажатии кнопки печатается Clicked плюс значения слайдеров.
Все работает, но есть один ньюанс - при каждом нажатии печатаеся новая строка. Ровно тоже самое будет с графиками - они начнут плодиться, что неудобно.
Для очистки надо воспользоваться объектом widgets.Output() и обрамить функцию для его использования, используя конструкцию with

При запуске этого кода мы получим элемены управления но ... ничего происходить не будет.
Т.е. при нажатии кнопки мы вообще ничего не увидим. Поэтому строкой ниже можно просто вывести созданный Output() - вот там все и будет отображаться

Теперь все заработало как надо - строка обновляется и не рисуется еще одна.
Ровно то же можно использовать для графиков.
На понимание этого у меня ушло пару недель "шаманства" - понял я это не сразу.
07 June 2020
Блокнот Юпитера
Повозившись с Spyder мне захотелось интерактивности. Пожалуй самый быстрый способ с Анакондой - это Блокнот Юпитера - Jupyter Notebook.
Посему сначала оставлю ссылку на руководство по его использованию
Jupyter Notebook для начинающих: учебник
Еще одно замечание: поскольку в Убунту у меня при установке Анаконды не поставились ярлыки для запуска, то запускал я из командной строки.
Так вот, каталогом для Юпитера будет тот каталог, в котором мы в терминале выполним jupiter-notebook ( путь к нему прописывается в PATH поэтому доступен он для запуска везде ).
То есть самый простой путь получить нужный каталог файлов - переместиться туда через cd и там запустить Юпитер.
Посему сначала оставлю ссылку на руководство по его использованию
Jupyter Notebook для начинающих: учебник
Еще одно замечание: поскольку в Убунту у меня при установке Анаконды не поставились ярлыки для запуска, то запускал я из командной строки.
Так вот, каталогом для Юпитера будет тот каталог, в котором мы в терминале выполним jupiter-notebook ( путь к нему прописывается в PATH поэтому доступен он для запуска везде ).
То есть самый простой путь получить нужный каталог файлов - переместиться туда через cd и там запустить Юпитер.
06 June 2020
Полезные ссылки по Pandas для начала
Работа с CSV средствами NumPy меня окончательно убедила в том, что надо переходить на Pandas. Парочка полезных ссылок для начала.
Аналитикам: большая шпаргалка по Pandas
Данная ссылка кроме всего прочего содержит ссылки на два модельных CSV файла, скачав которые, можно потренироваться в работе с Pandas.
Python 3 Pandas: Объекты Series и DataFrame. Построение Index
Вторую ссылку я скорее использовал как справочник - там пристыкованы картинки ( pdf ) которые хороши как наглядные шпаргалки.
Для работы с Pandas я использовал тот же самый Spyder в том числе его консоль IPyhon.
Аналитикам: большая шпаргалка по Pandas
Данная ссылка кроме всего прочего содержит ссылки на два модельных CSV файла, скачав которые, можно потренироваться в работе с Pandas.
Python 3 Pandas: Объекты Series и DataFrame. Построение Index
Вторую ссылку я скорее использовал как справочник - там пристыкованы картинки ( pdf ) которые хороши как наглядные шпаргалки.
Для работы с Pandas я использовал тот же самый Spyder в том числе его консоль IPyhon.
05 June 2020
Читаем csv средствами NumPy
Модель проверяется по реальным данным. Одним из наиболее употребительных методов их хранения, являются CSV файлы или ВеличиныРазделенныеЗапятой. Самый очевидный способ их чтения - воспользоваться функциями библиотеки NumPy, а именно функцией loadtxt.
Удобство в том, что можно несколько колонок прочитать одновременно.
Но тогда надо указывать параметр unpack=True чтобы сделать декомпозицию и присвоить данные нескольким массивам, перечисленным через запятую
Вот пример CSV файла

Как можно видеть первой строчкой идет заголовок, его надо пропустть, для этого ставим параметр skiprows=1. Другим параметром usecols = (1,2) укзываем что надо читать колонки 1 и 2.
Код:
dIreal, Ireal = np.loadtxt('CovidData.csv',
delimiter=',', # разделитель - запятая
usecols = (1,2), # читаем 1 и 2 колонки ( нумерация с нуля )
skiprows=1, # пропускаем первую строку заголовка
unpack=True) # декомпозиция колонок на массивы ( списки )
После выполнения колонки dI и Isum окажутся в массивах dIreal и Ireal соответственно.
Для чтения данных для колонк D и R нам надо пропустить строки - они начинаются позже. Код будет аналогичный, но с бОльшим пропуском
Dreal, Rreal = np.loadtxt('CovidData.csv',
delimiter=',',
usecols = (4,6),
skiprows=16,
unpack=True)
Однако "шаманство" начинается если нам надо прочитать даты, особенно если они имеют другой формат - в данном случае надо применять конвертер или лямбда-функцию конвертирования данных. Код:
import datetime as dt
# лямбда-функция конвертирования данных
conv2date = lambda x: dt.datetime.strptime ( x.decode("utf-8"), '%d.%m.%Y')
datesMain = np.loadtxt('CovidData.csv',
delimiter=',',
usecols = (0), # первая колонка
converters={0:conv2date}, # применяем конвертер
dtype='datetime64[D]', # указываем целевой тип данных
skiprows=1 )
Таким образом можно прочитать и даты - в моем случае я для дат использовал тире, как более читаемый символ-разделитель в CSV.
Однако такой набор кода не очень удобен, поэтому я стал смотреть в сторону библиотеки для работы с данными - Pandas.
Удобство в том, что можно несколько колонок прочитать одновременно.
Но тогда надо указывать параметр unpack=True чтобы сделать декомпозицию и присвоить данные нескольким массивам, перечисленным через запятую
Вот пример CSV файла

Как можно видеть первой строчкой идет заголовок, его надо пропустть, для этого ставим параметр skiprows=1. Другим параметром usecols = (1,2) укзываем что надо читать колонки 1 и 2.
Код:
dIreal, Ireal = np.loadtxt('CovidData.csv',
delimiter=',', # разделитель - запятая
usecols = (1,2), # читаем 1 и 2 колонки ( нумерация с нуля )
skiprows=1, # пропускаем первую строку заголовка
unpack=True) # декомпозиция колонок на массивы ( списки )
После выполнения колонки dI и Isum окажутся в массивах dIreal и Ireal соответственно.
Для чтения данных для колонк D и R нам надо пропустить строки - они начинаются позже. Код будет аналогичный, но с бОльшим пропуском
Dreal, Rreal = np.loadtxt('CovidData.csv',
delimiter=',',
usecols = (4,6),
skiprows=16,
unpack=True)
Однако "шаманство" начинается если нам надо прочитать даты, особенно если они имеют другой формат - в данном случае надо применять конвертер или лямбда-функцию конвертирования данных. Код:
import datetime as dt
# лямбда-функция конвертирования данных
conv2date = lambda x: dt.datetime.strptime ( x.decode("utf-8"), '%d.%m.%Y')
datesMain = np.loadtxt('CovidData.csv',
delimiter=',',
usecols = (0), # первая колонка
converters={0:conv2date}, # применяем конвертер
dtype='datetime64[D]', # указываем целевой тип данных
skiprows=1 )
Таким образом можно прочитать и даты - в моем случае я для дат использовал тире, как более читаемый символ-разделитель в CSV.
Однако такой набор кода не очень удобен, поэтому я стал смотреть в сторону библиотеки для работы с данными - Pandas.
Небольшая шпаргалка по matplotlib
Запомню для себя небольшую шпаргалку для matplotlib
Построение графиков в Python при помощи Matplotlib
Построение графиков в Python при помощи Matplotlib
Даты на графиках matplotlib
Даты янляются одним из хитрых типов данных в языках программирования, которые требуют специальной обработки.
При построении графиков также хочется чтобы график был читаемым и в нем не было избыточности и, как следствие, наложение подписей осей друг на друга.
Чтобы вывести даты этим способом по оси абсцисс в matplotlib приходится "шаманить" - т.е. вызывать дополнительные функции.
В простом случае надо получить доступ к осям - это делает метод gca() или Get Current Axes.
Далее получаем доступ к оси абсцисс xaxis и уже у нее вызываем методы настройки. В моем случае, поскольку данные по короновирусу ограничены только этим годом, то нет смысл выводить год и на нем можно сократить.
Код:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
...
# определяем форматирование - день и месяц через тире
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter("%d-%m"))
# ставим интервал в 15 дней между штрихами ( ticks ) в 15 дней
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=15))
# применяем форматирование
plt.gcf().autofmt_xdate()

После этого график по оси абсцисс подписан как нам надо - только месяц и день.
При построении графиков также хочется чтобы график был читаемым и в нем не было избыточности и, как следствие, наложение подписей осей друг на друга.
Чтобы вывести даты этим способом по оси абсцисс в matplotlib приходится "шаманить" - т.е. вызывать дополнительные функции.
В простом случае надо получить доступ к осям - это делает метод gca() или Get Current Axes.
Далее получаем доступ к оси абсцисс xaxis и уже у нее вызываем методы настройки. В моем случае, поскольку данные по короновирусу ограничены только этим годом, то нет смысл выводить год и на нем можно сократить.
Код:
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
...
# определяем форматирование - день и месяц через тире
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter("%d-%m"))
# ставим интервал в 15 дней между штрихами ( ticks ) в 15 дней
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=15))
# применяем форматирование
plt.gcf().autofmt_xdate()

После этого график по оси абсцисс подписан как нам надо - только месяц и день.
04 June 2020
Научный Питон - полезные ссылки.
Первая ссылка - книга "Введение в научный Python" которую рекомендую пробежать глазом, и которая хорошо описывает богатство этой среды
Введение в научный Python
Вторая ссылка содержит кучу ссылок на разные руководства и трюки по Pandas.
Детально я ее не смотрел, хотя возможно некоторые приведенные ссылки оттуда я уже ранее смотрел
Pandas Tutorials, Articles & Videos
Ну и третью пока оставляю для себя ( не пробовал ) - чтение csv-файлов выложенных в открытый доступ на Google Drive
Pandas: How to read CSV file from google drive public?
Введение в научный Python
Вторая ссылка содержит кучу ссылок на разные руководства и трюки по Pandas.
Детально я ее не смотрел, хотя возможно некоторые приведенные ссылки оттуда я уже ранее смотрел
Pandas Tutorials, Articles & Videos
Ну и третью пока оставляю для себя ( не пробовал ) - чтение csv-файлов выложенных в открытый доступ на Google Drive
Pandas: How to read CSV file from google drive public?
02 June 2020
Формирование массива дат в Питоне
При моделирование по той же SEIRD модели хочется иметь привязку к реальным датам, особенно если требуется сравнить модельный данные с реальными. Просто запоминаю для себя как сделать массив таких дат:
import matplotlib.dates as mdates
import datetime as dt
Ndays = 47 # требуемое количество дней
# стартовая дата - 26 марта 2020
now = dt.datetime ( 2020,3,26)
# конечная дата по дельте дней
then = now + dt.timedelta(days=Ndays)
# формируем массив дат
days = mdates.drange(now,then,dt.timedelta(days=1))
Однако, увы, в Spyder в переменных это будет показываться как число

import matplotlib.dates as mdates
import datetime as dt
Ndays = 47 # требуемое количество дней
# стартовая дата - 26 марта 2020
now = dt.datetime ( 2020,3,26)
# конечная дата по дельте дней
then = now + dt.timedelta(days=Ndays)
# формируем массив дат
days = mdates.drange(now,then,dt.timedelta(days=1))
Однако, увы, в Spyder в переменных это будет показываться как число

Убунту и VirtualBox
Я использую Убунту в виртуальной машине и для этого использую VirtualBox. Чтобы можно было копировать буфер, в частности строки, между основной операционной системой и Убунтой в виртуальной, требуется в Убунту поставить дополнения. Однако они идут в виде исходников и в инсталляции по-умолчанию не ставятся. Для этого надо поставить утилиты для билда в Убунту.
sudo apt install build-essential dkms
После этого их можно поставить. Также требуется в настройках виртуальной машины разрешить доступ к буферу обмена в две стороны, если требуется копировать между основной ОС и обратно.
sudo apt install build-essential dkms
После этого их можно поставить. Также требуется в настройках виртуальной машины разрешить доступ к буферу обмена в две стороны, если требуется копировать между основной ОС и обратно.
01 June 2020
Паук и графика - о размерах
Как я ранее говорил - Spyder вполне себе годится на первых этапах.
Например, когда я гонял SEIRD модель вначале, то просто менял параметры - например количество дней N непосредственно в окне кода ( на картинке ниже это строка 47 )

а после просто запускал программу и график обновлялся.
Однако это последний график - Spyder хранит всю историю

Что, впрочем не межает взять и уменьшить это окно истории до нуля, хотя чем больше будет картинок в истории, тем более медленным будет последущие запуски.
И это неудобно - приходится руками чистить эту историю - там есть опции удаления.
Второй недостаток это то, что если попробовать сохранить картинку, нажав на иконку дискеты ( кто-нибудь помнит что это такое ? ), то ... она будет очень малого размера. Наглядно это можно посмотреть, открыв ее в IrfanView:

Как можно догадаться - такая картинка очень плохо годится для публикации. Поэтому приходится искать другие варианты привести ее в порядок...
Например, когда я гонял SEIRD модель вначале, то просто менял параметры - например количество дней N непосредственно в окне кода ( на картинке ниже это строка 47 )

а после просто запускал программу и график обновлялся.
Однако это последний график - Spyder хранит всю историю

Что, впрочем не межает взять и уменьшить это окно истории до нуля, хотя чем больше будет картинок в истории, тем более медленным будет последущие запуски.
И это неудобно - приходится руками чистить эту историю - там есть опции удаления.
Второй недостаток это то, что если попробовать сохранить картинку, нажав на иконку дискеты ( кто-нибудь помнит что это такое ? ), то ... она будет очень малого размера. Наглядно это можно посмотреть, открыв ее в IrfanView:

Как можно догадаться - такая картинка очень плохо годится для публикации. Поэтому приходится искать другие варианты привести ее в порядок...
Скриншоты в Убунту - все хитро
Рано я порадовался что поставил IrfanView ...
Все оказалось не так просто в плане получения снимков экрана:
Если я сделал снимок нажатием Ctrl-PrnScr то в IrfanView он ... не копируется. Поэтому приходится пользоваться посредничеством Nomacs.
Последовательность такая:
Вероятно есть возможность его сохранения непосредственно в файл, но я как-то не хочу забивать файловую систему ненужными промежуточными сырыми графическими файлами.
Все оказалось не так просто в плане получения снимков экрана:
Если я сделал снимок нажатием Ctrl-PrnScr то в IrfanView он ... не копируется. Поэтому приходится пользоваться посредничеством Nomacs.
Последовательность такая:
- Делаем снимок нажатием Ctrl-PrnScr
- Запускаем Nomacs и вставляем его туда
- В Nomacs делаем Ctrl-C и копируем снимок в буфер
- Запускаем IrfanView и через Ctrl-V вставляем
Вероятно есть возможность его сохранения непосредственно в файл, но я как-то не хочу забивать файловую систему ненужными промежуточными сырыми графическими файлами.
Subscribe to:
Posts (Atom)